在爬虫入门到精通第五讲中,我们了解了如何用正则表达式去抓取我们想要的内容.这一章我们来学习如何更加简单的来获取我们想要的内容.
xpath的解释
XPath 即为XML 路径语言(XML Path Language),它是一种用来确定XML文档中某部分位置的语言。XPointer 与XSL 间的语法模型。但是XPath很快的被开发者采用来当作小型查询语言 。
XPath的基本使用 要使用xpath我们需要下载lxml,在爬虫入门到精通-环境的搭建 这一章也说明怎么装,如果还没有安装的话,那就去下载安装吧
直接看代码实战吧。
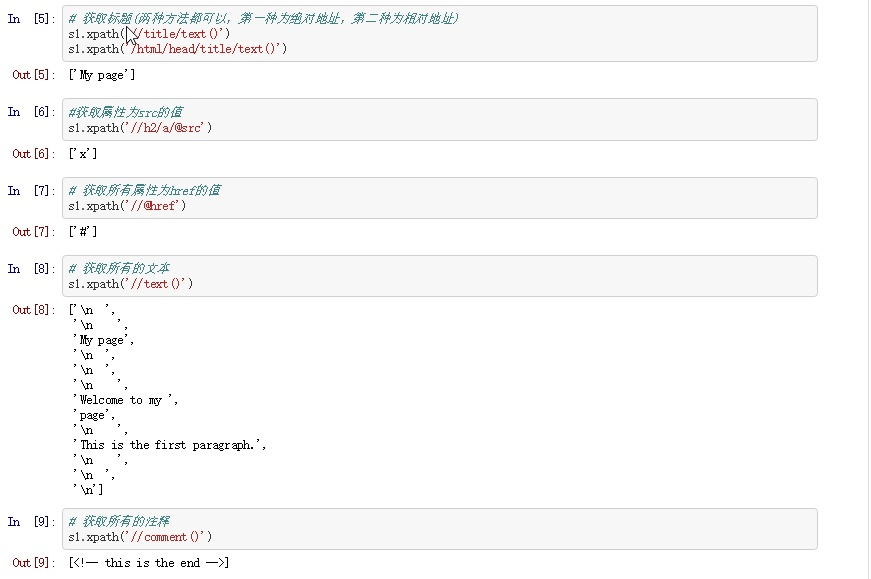
第一个案列 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 from lxml import etreedef getxpath (html ): return etree.HTML(html) sample1 = """<html> <head> <title>My page</title> </head> <body> <h2>Welcome to my <a href="#" src="x">page</a></h2> <p>This is the first paragraph.</p> <!-- this is the end --> </body> </html> """ s1 = getxpath(sample1) s1.xpath('//title/text()' ) s1.xpath('/html/head/title/text()' )
相对路径与绝对路径
总结及注意事项
获取文本内容用 text()
获取注释用 comment()
获取其它任何属性用@xx,如
@href
@src
@value
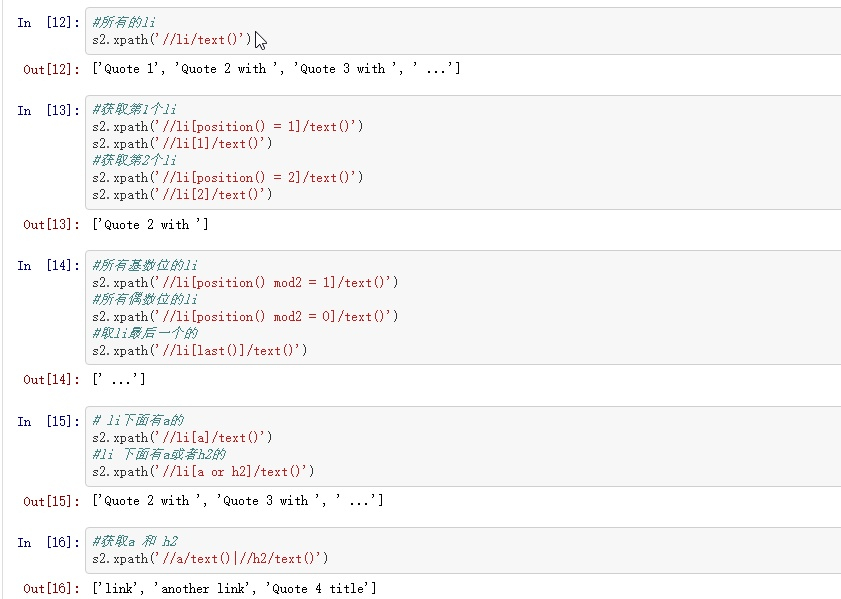
第二个案列 1 2 3 4 5 6 7 8 9 10 11 12 13 sample2 = """ <html> <body> <ul> <li>Quote 1</li> <li>Quote 2 with <a href="...">link</a></li> <li>Quote 3 with <a href="...">another link</a></li> <li><h2>Quote 4 title</h2> ...</li> </ul> </body> </html> """ s2 = getxpath(sample2)
总结及注意事项
上面的li 可以更换为任何标签,如 p、div
位置默认以1开始的 最后一个用 li[last()] 不能用 li[-1]
这个一般在抓取网页的下一页,最后一页会用到
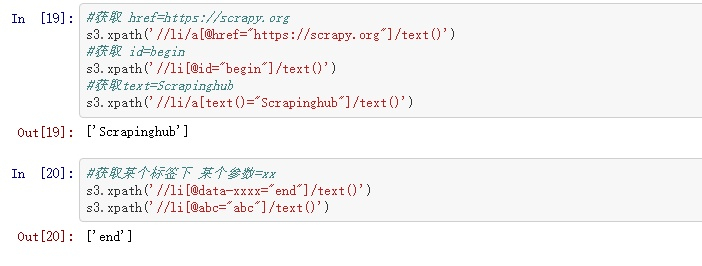
第三个案列 1 2 3 4 5 6 7 8 9 10 11 12 13 14 sample3 = """<html> <body> <ul> <li id="begin"><a href="https://scrapy.org">Scrapy</a>begin</li> <li><a href="https://scrapinghub.com">Scrapinghub</a></li> <li><a href="https://blog.scrapinghub.com">Scrapinghub Blog</a></li> <li id="end"><a href="http://quotes.toscrape.com">Quotes To Scrape</a>end</li> <li data-xxxx="end" abc="abc"><a href="http://quotes.toscrape.com">Quotes To Scrape</a>end</li> </ul> </body> </html> """ s3 = getxpath(sample3)
总结及注意事项
//input[@name="_xsrf"]/@value
第四个案列 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 sample4 = u""" <html> <head> <title>My page</title> </head> <body> <h2>Welcome to my <a href="#" src="x">page</a></h2> <p>This is the first paragraph.</p> <p class="test"> 编程语言<a href="#">python</a> <img src="#" alt="test"/>javascript <a href="#"><strong>C#</strong>JAVA</a> </p> <p class="content-a">a</p> <p class="content-b">b</p> <p class="content-c">c</p> <p class="content-d">d</p> <p class="econtent-e">e</p> <p class="heh">f</p> <!-- this is the end --> </body> </html> """ s4 = etree.HTML(sample4)
总结及注意事项
想要获取某个标签下所有的文本(包括子标签下的文本),使用string
如 <p>123<a>来获取我啊</a></p>,这边如果想要得到的文本为123来获取我啊”,则需要使用string
starts-with 匹配字符串前面相等contains 匹配任何位置相等当然其中的(@class,"content")也可以根据需要改成(text(),"content")或者其它属性(@src,"content")
最后再次总结一下 看完本篇文章后,你应该要
本文作者 :高金本文地址 : https://igaojin.me/2018/02/03/网页的解析之XPATH/ 版权声明 :转载请注明出处!