大家写爬虫的,肯定知道如何伪造请求头了,那么你们是如何做的呢?
首先,来看看我之前是如何做的,有多烦我就不说了…
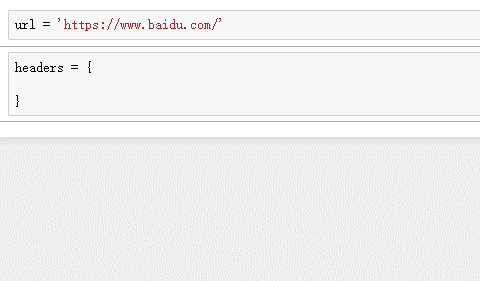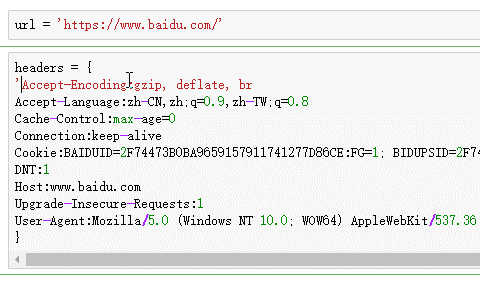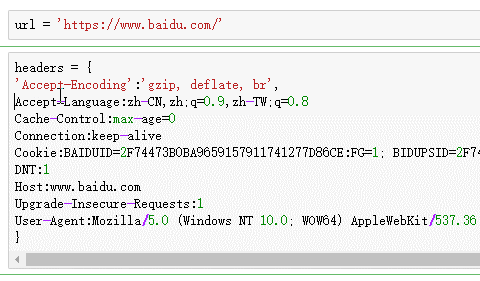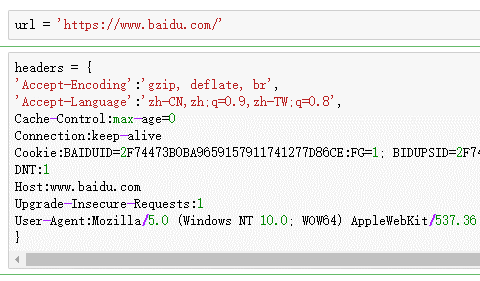
如果有小伙伴是和我一样,那么请帮忙把这篇文章分享出去~
那我现在怎么是怎么做的呢?
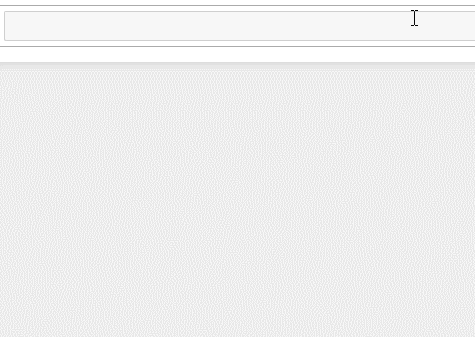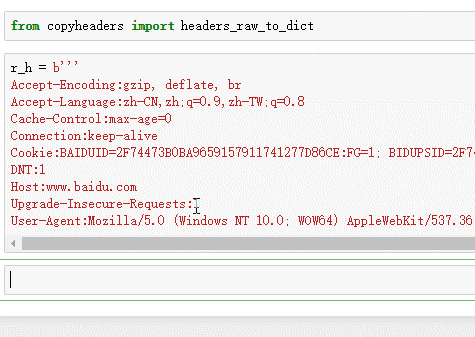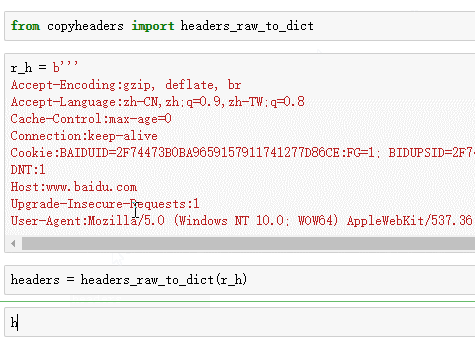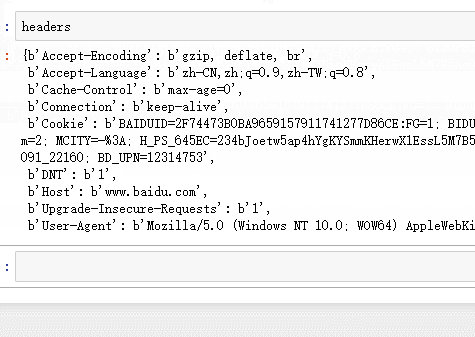
可以发现复制请求头很简单了,只要把请求头全部copy下来,然后用headers_raw_to_dict 转一下,就直接变成了dict了.
如何安装呢
pip install copyheaders
如何使用呢
先找到你要复制的请求头,并且复制
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
from copyheaders import headers_raw_to_dict
impore requests
r_h = b'''
Accept:text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8
Accept-Encoding:gzip, deflate, br
Accept-Language:zh-CN,zh;q=0.9,zh-TW;q=0.8
Cache-Control:max-age=0
Connection:keep-alive
Cookie:_gauges_unique_month=1; _gauges_unique_year=1; _gauges_unique=1; _gauges_unique_hour=1; _gauges_unique_day=1
DNT:1
Host:httpbin.org
Referer:https://httpbin.org/
Upgrade-Insecure-Requests:1
User-Agent:Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36
'''
headers = headers_raw_to_dict(r_h)
z = requests.get('https://httpbin.org/headers',headers=headers
|
项目地址在copyheaders
本文作者:高金
本文地址: https://igaojin.me/2018/02/03/爬虫小工具-copyheader/
版权声明:转载请注明出处!
