本文章属于爬虫入门到精通系统教程第八讲
本次我们会讲解两个知识点
- 异步加载
- headers中的Accept
本次我们要抓取的是花瓣网美女照片美女花瓣,陪你做生活的设计师(发现、采集你喜欢的美女图片)花瓣网(http://huaban.com/favorite/beauty/)
本次我们会用到的辅助包
scrapy/parsel (https://github.com/scrapy/parsel)(假如你用过scrapy,那么一定不陌生,这就是其中提取器)
Parsel is a library to extract data from HTML and XML using XPath and CSS selectors
简单来讲就是集成了xpath和css,只要你会xpath的话,那么用法没有什么区别
1 | from parsel import Selector |
安装方法: pip install parsel
scrapinghub/js2xml(https://github.com/scrapinghub/js2xml)
Convert Javascript code to an XML document
简单来讲就是 将JavaScript代码转换为xml文档。然后可以使用xpath从JavaScript中提取数据,不用写一堆正则了。
1 | import js2xml |
安装方法: pip install js2xml
开始爬虫
我们先打开美女花瓣,陪你做生活的设计师(发现、采集你喜欢的美女图片)花瓣网(http://huaban.com/favorite/beauty/)
页面分析
如果我们想把这里面所有美女照片抓取下来的话,那么我们的操作步骤应该是这样的
1.打开首页的每一个”相框”,然后点进去
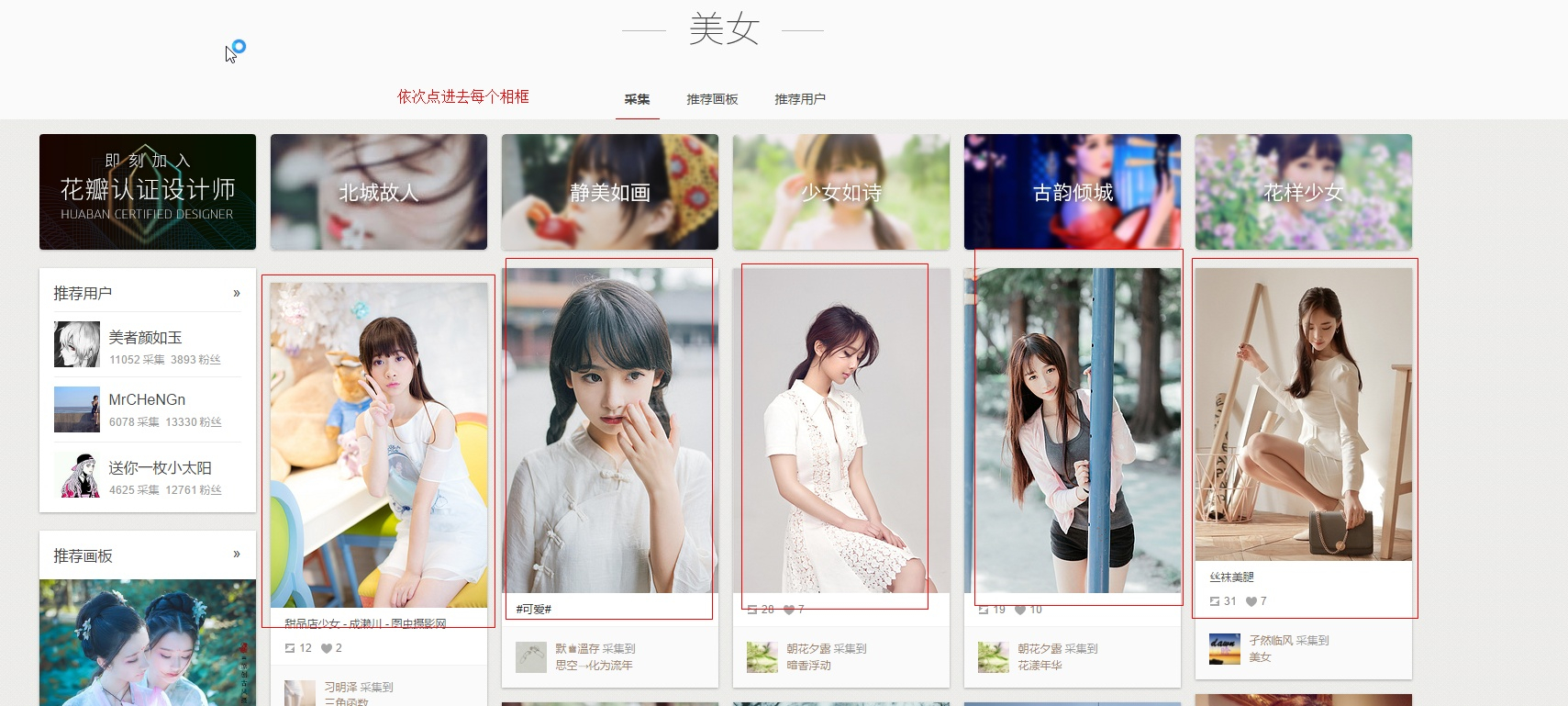
2.获取所有图片的链接,然后下载下来
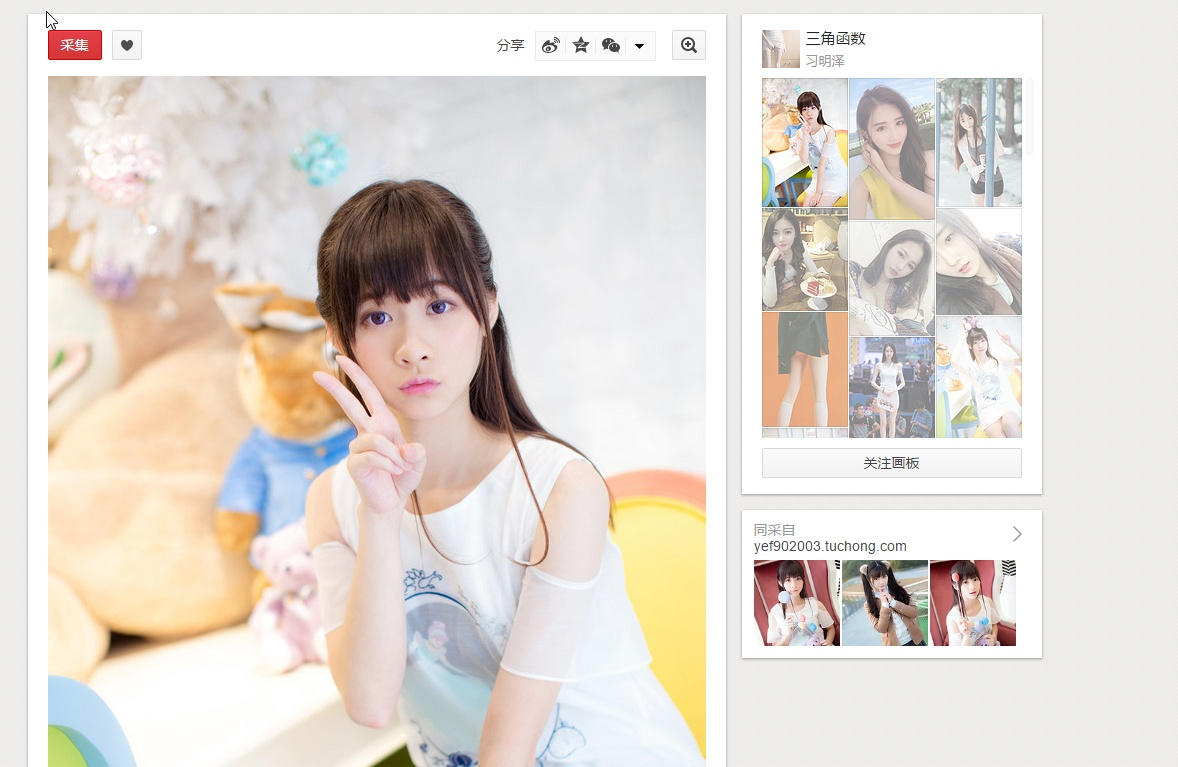
程序实现:
用程序实现的话,也是挺简单的
- 获取首页所有“相框”的链接
- 点进去每个链接
- 获取详情页的所有图片地址
- 下载图片
代码:
获取首页所有“相框”的链接
我们打开美女花瓣,陪你做生活的设计师(发现、采集你喜欢的美女图片)花瓣网(http://huaban.com/favorite/beauty/)
按F12
点击如图所示的位置
点击任何一个相框,然后你会看到网页的源代码自动会跳到你当前选中的地方
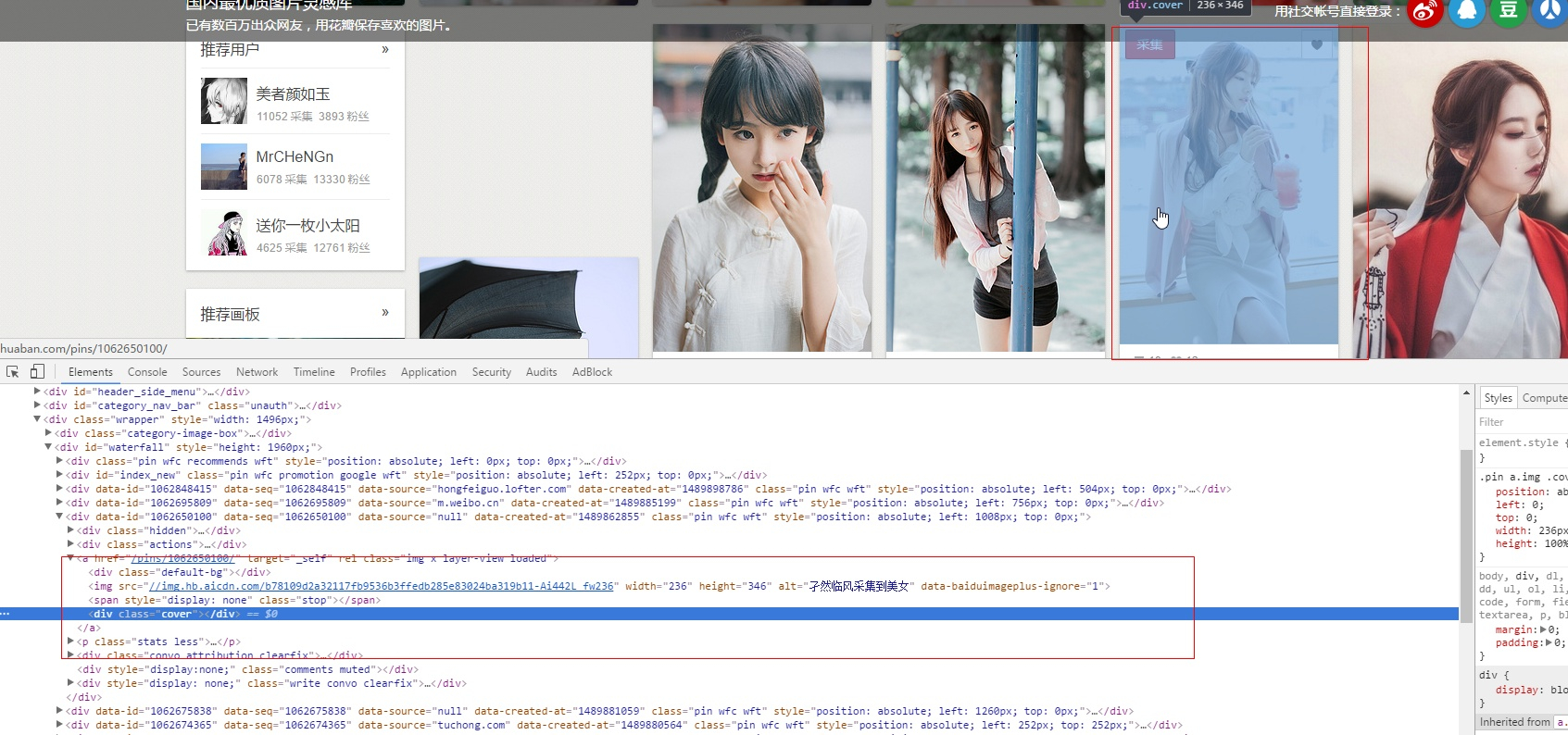
然后你就可以在这附近找找你想要的链接地址(可以看到/pins/1062650100/,我们可以打开这个地址看看,确认下是我们想要找的)
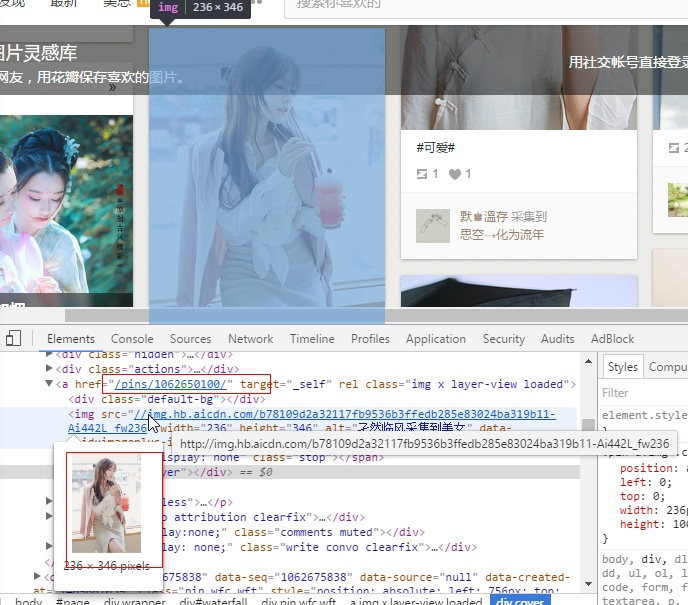
可以看到图片是一样的,说明我们要找的没错
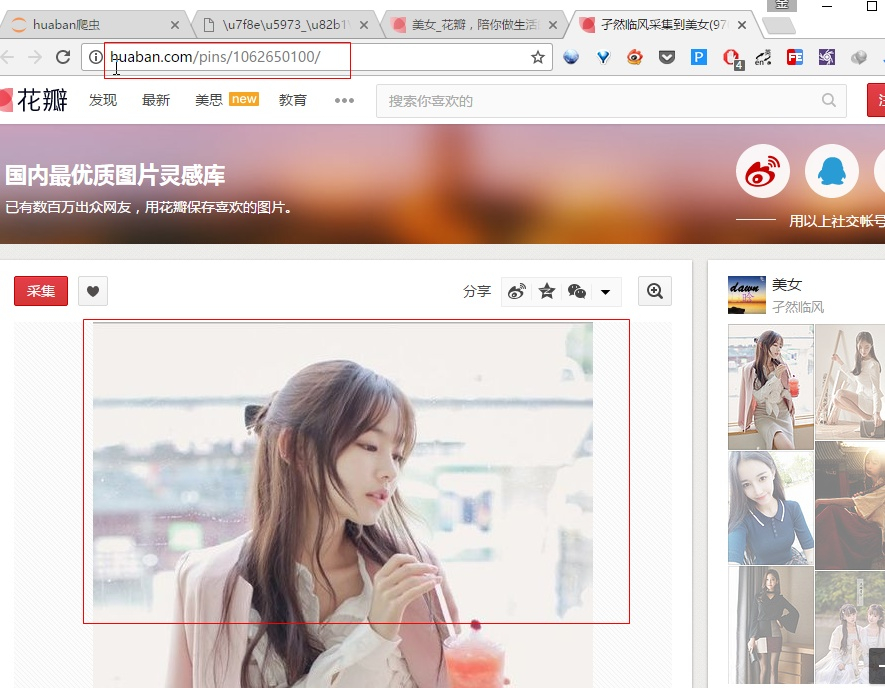
那么既然我们找到了需要的链接,接下来就是用程序定位到这了。
可以看到链接这边有个
class=”img x layer-view loaded”,那么我们可以用以下xpath来获取地址了//a[@class=”img x layer-view loaded”]/@href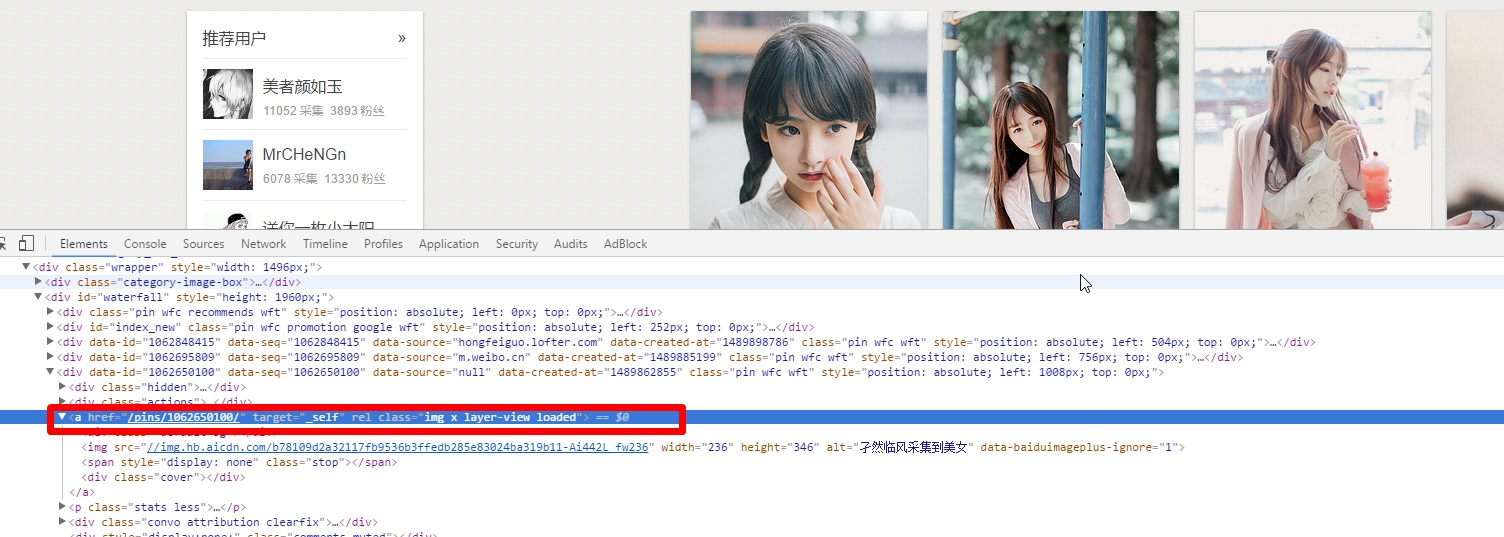
用代码实现:
1 | import requests |
这边为什么会返回空呢?不是应该返回所有链接的么?
我们可以查看下网页源代码,可以发现的内容都是通过js渲染上去的,所以我们才获取不到内容(这个可以用js2xml来解析,先放在这里,到详情页再来处理。)


所谓的异步加载
我们还是打开美女花瓣,陪你做生活的设计师(发现、采集你喜欢的美女图片)花瓣网(http://huaban.com/favorite/beauty/)
可以发现我们把页面拖动到最下面,会自动加载出新的内容(整个页面没有跳转,这就是所谓的异步加载。有些网页是需要手动点击“加载更多的”,原理都是一样的)
获取异步加载的请求
打开F12
拖动到页面最下面(有些网站是点击加载更多)
注意 我有勾选”xhr”
可以看到每次页面到最底部,都会发送一个请求。这个请求就是所谓的异步加载请求。
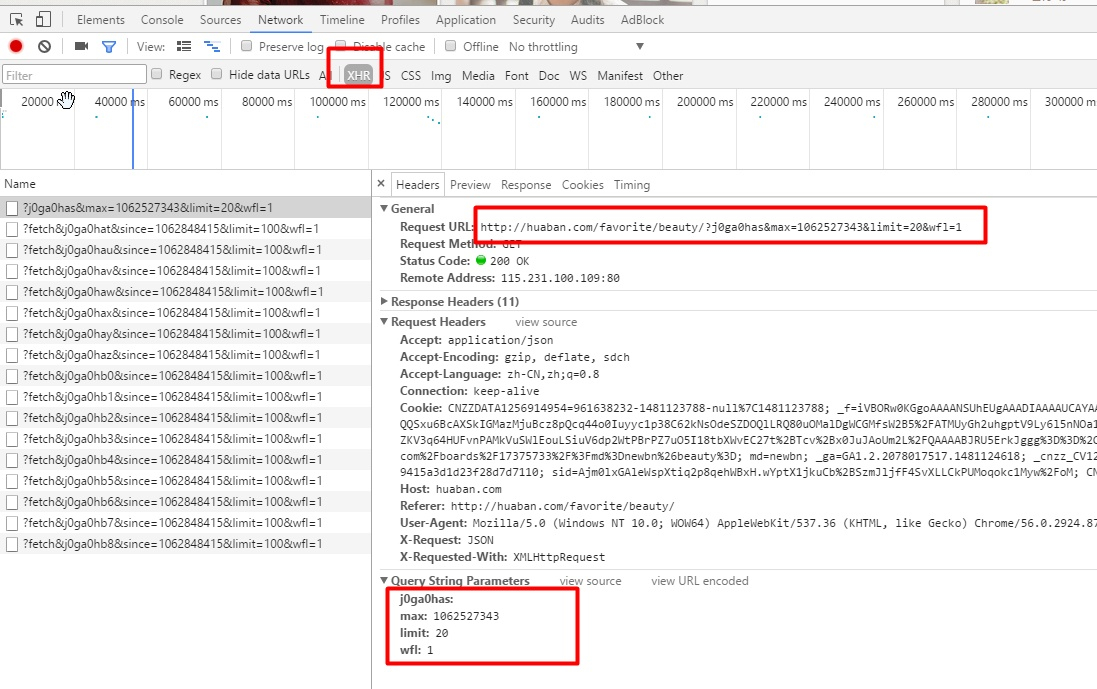
可以看到请求的参数如下:
j0ga0has:
max:1062527343
limit:20
wfl:1
j0ga0has第一个参数不知道是怎么回事,先放着max是 最上面的pin_idlimit是每次返回的条数- 有人可能会问,你怎么知道这个参数是干嘛的?其实都是试出来的(或者说看出来的)
- 如下图的
pin_id,可以发现下一条请求的max就是上一条请求获取到的最后一个pin_id 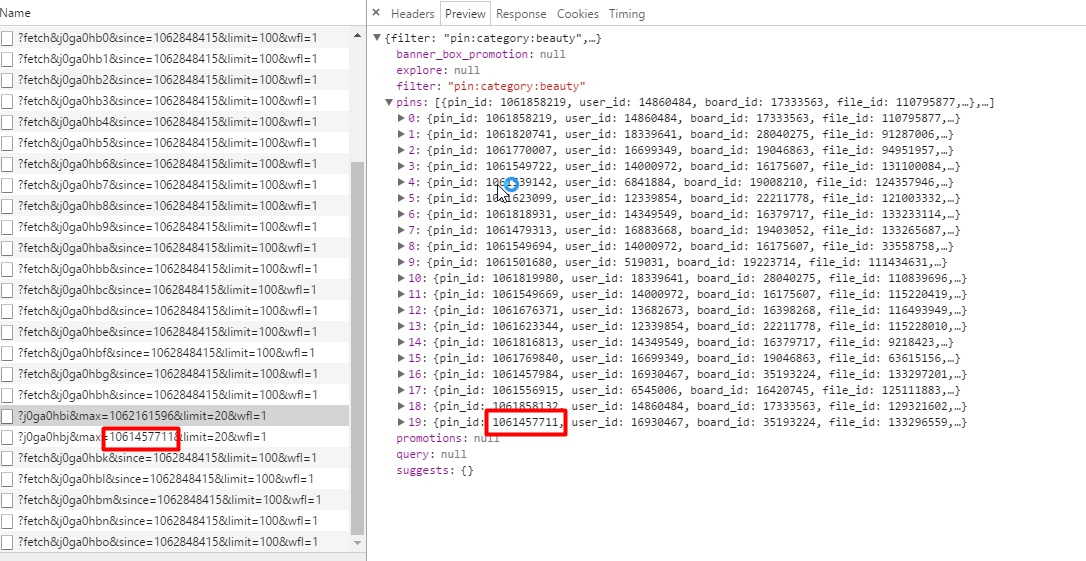
- 我们查看返回值,发现竟然是json格式的,这样的话,都不需要我们解析了,那我们找找我们需要的链接地址在哪。
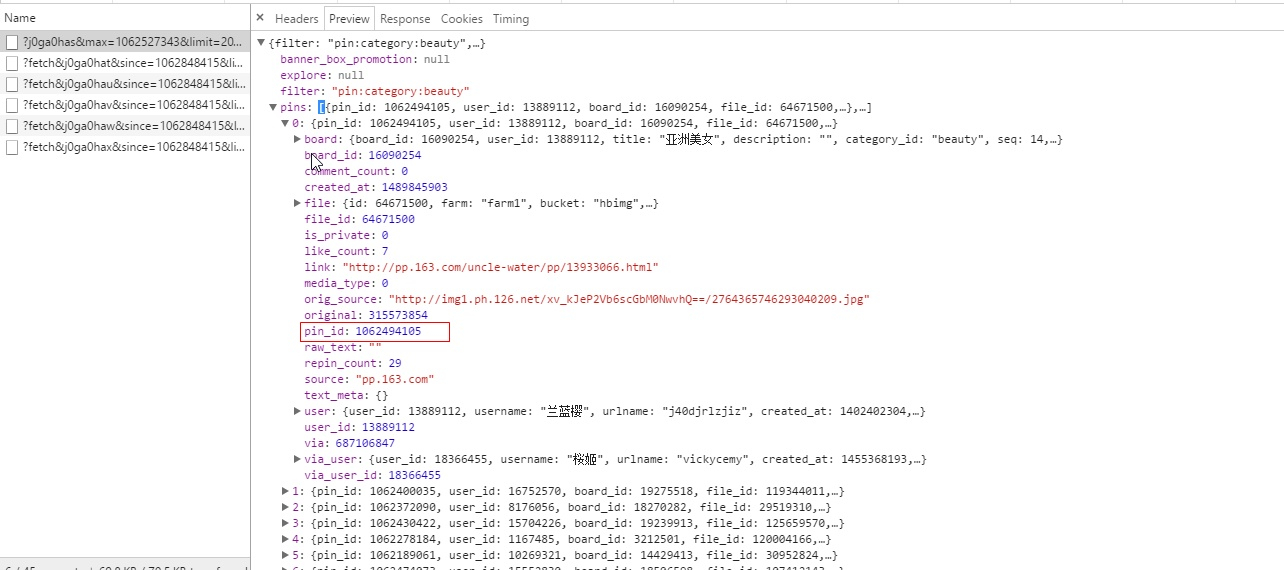
- 发现链接地址就是由pin_id拼接而成的,所以我们只要获取到这个pin_id就行。
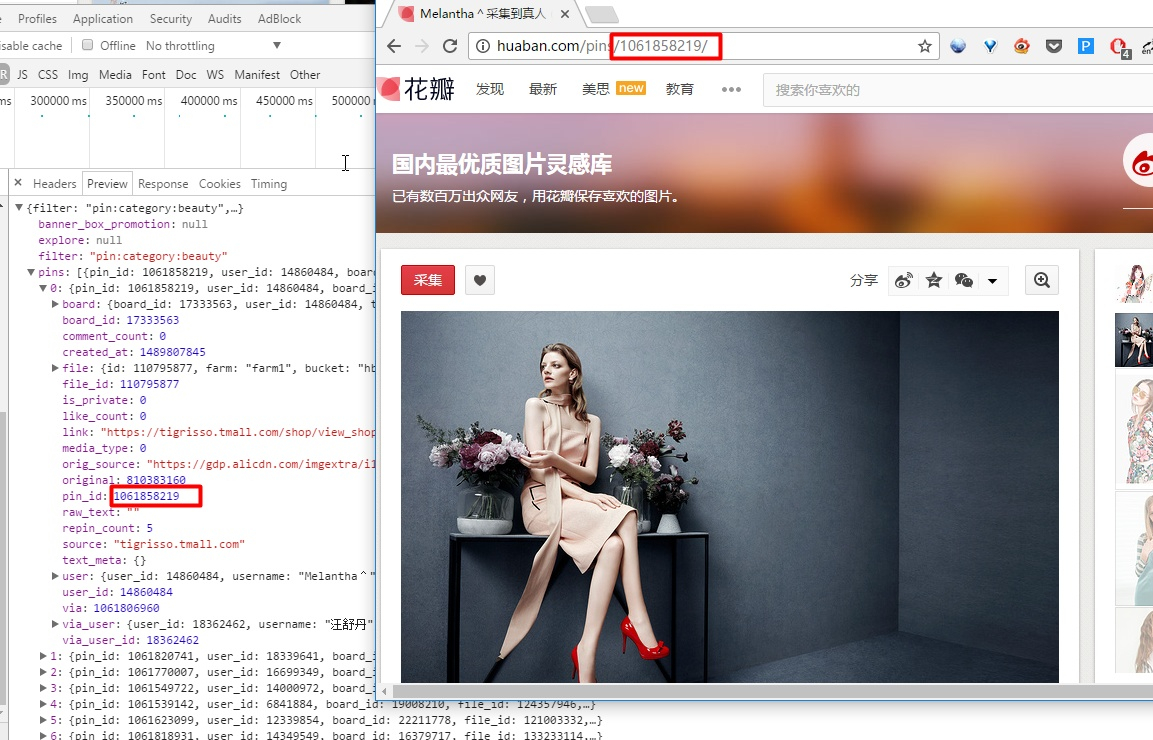
用程序来实现:
1 | url = ‘http://huaban.com/favorite/beauty/‘ |
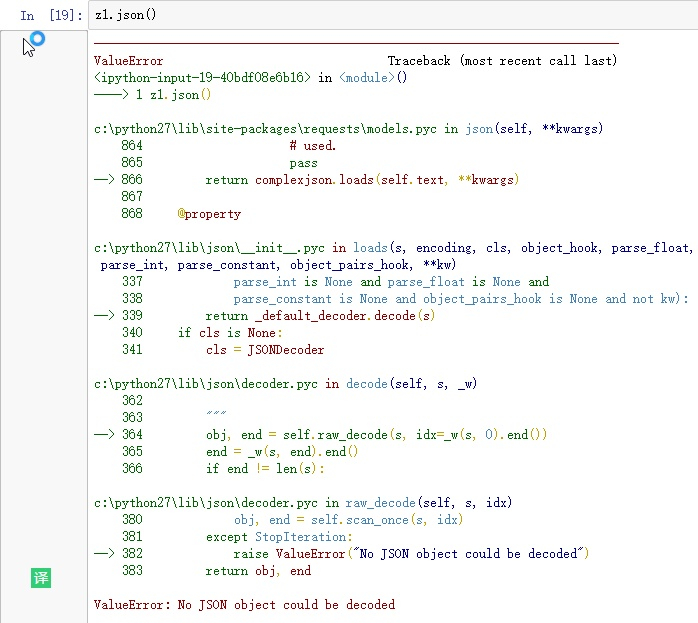
然后发现竟然报错了。。。
为什么呢?我们查看请求的时候就是jsno格式的啊
我们打印下源代码看看
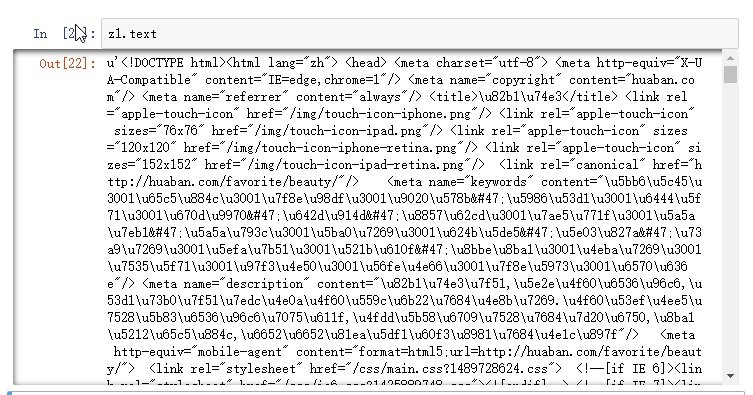
你会看到竟然是<!DOCTYPE html><html这样的,但是我们上面查看请求的时候,明明是如下图这样的啊
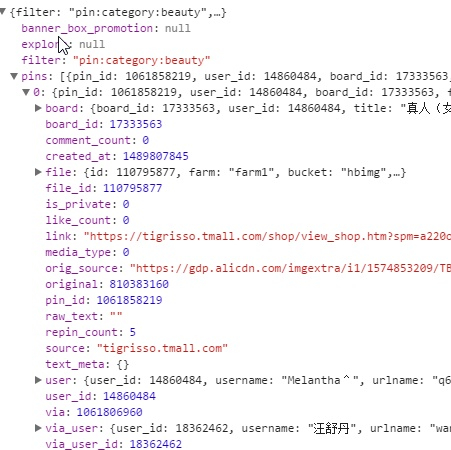
那么到底是哪里出了问题呢?
我们再次查看之前我们看到的异步请求
可以发现它有几个 特别的请求头
指定了格式为json ,那么我们加上去看看呢
1 | Accept:application/json |
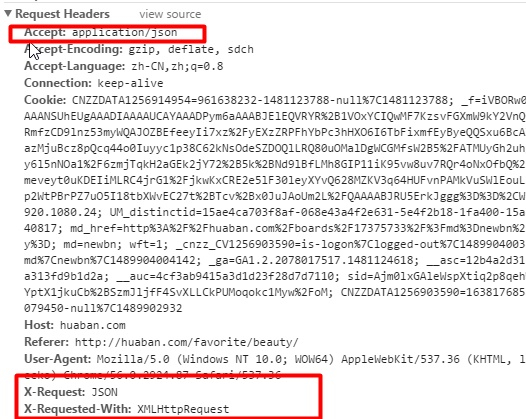
1 | headers1 = { ‘User-Agent’:’Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36’, ‘Accept’:’application/json’, ‘X-Request’:’JSON’, ‘X-Requested-With’:’XMLHttpRequest’ } |

可以看到返回值和我们之前一样了。
获取pin_id
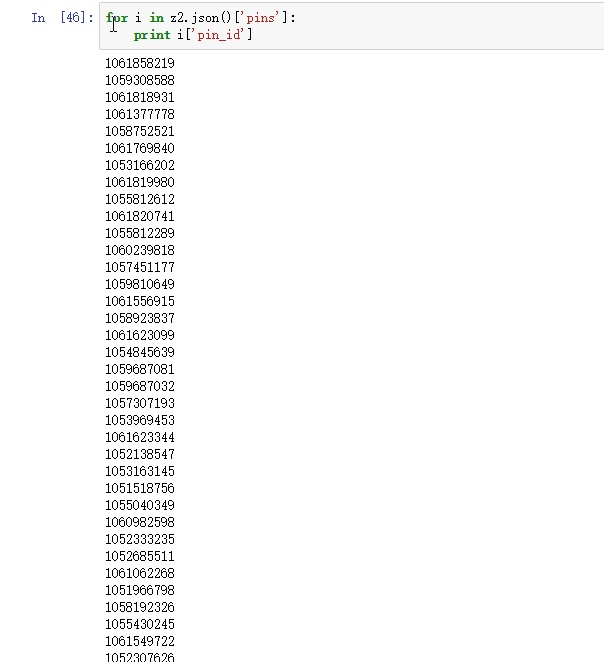
最后只要把pin_id拼接成url就可以了,如果你想要爬取所有的图片的话,那么你只需要把最后的pin_id 传入给max,再请求一次,直到pins为空为止
在上面我们已经获取到了所有的详情页的地址,那么我们现在只要获取到图片链接就行
- 随便打开一个详情页花瓣(http://huaban.com/pins/1062650100/)
- 查看图片地址
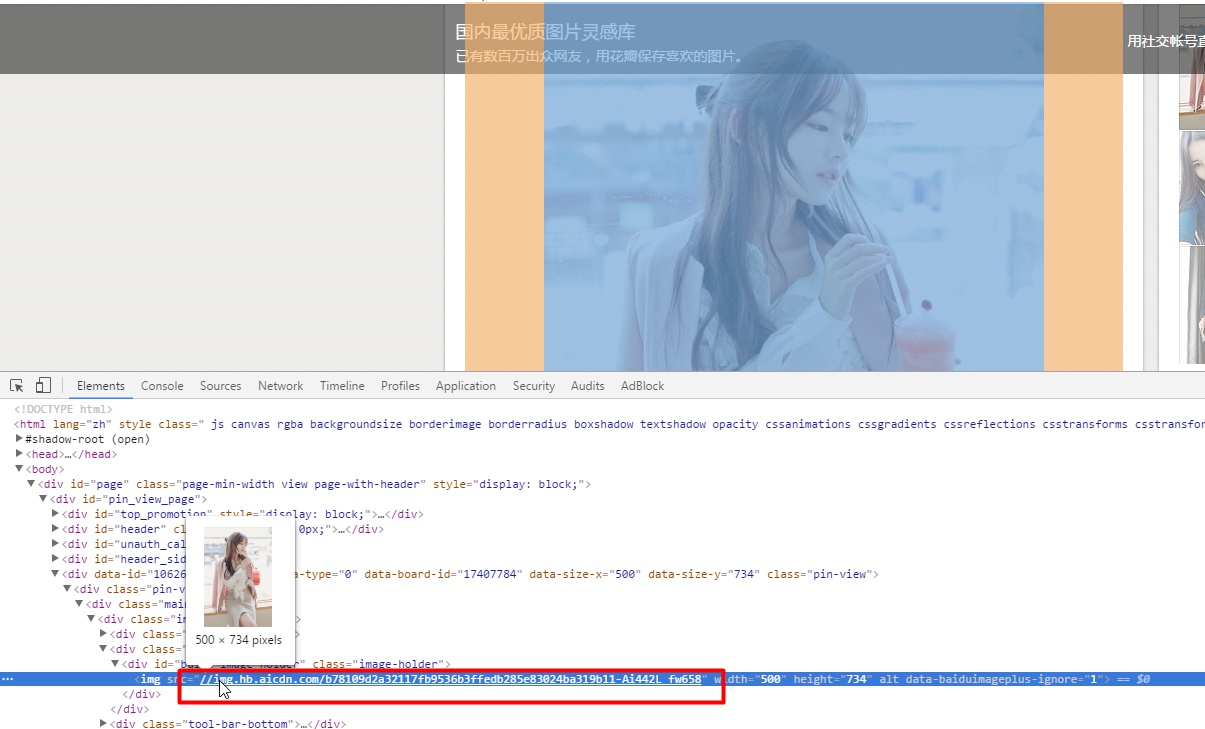
- 复制图片地址到网页源代码里面找找看
- 全部复制,发现没有找到
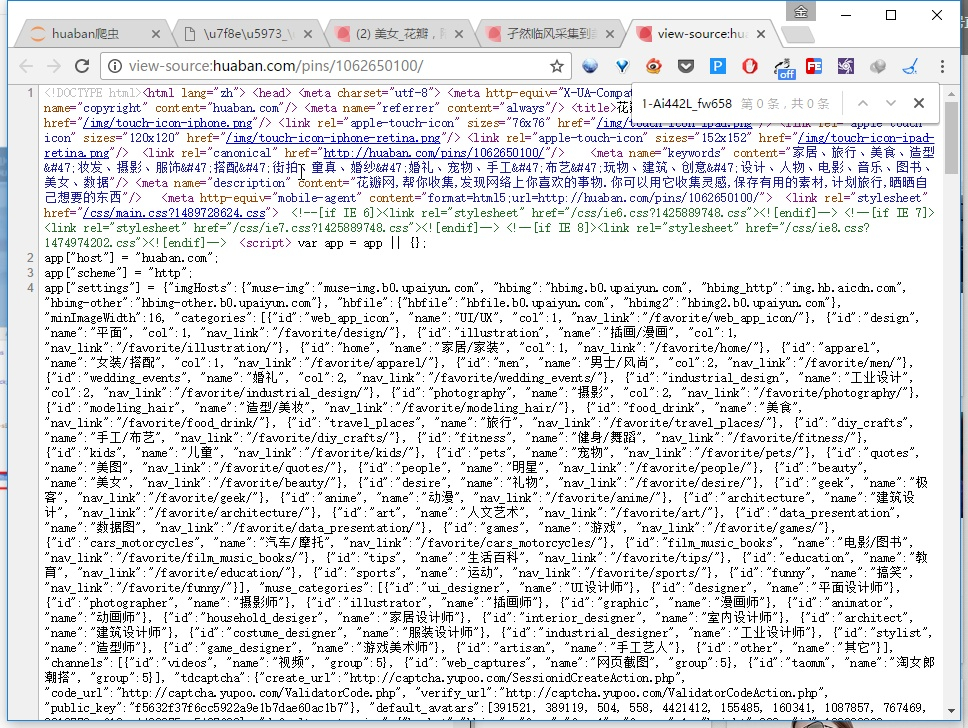
- 那么我们复制一部分
- 可以看到已经找到了,这边你也可以用正则表达式,来匹配所有的地址,但是太麻烦了,我们可以用
js2xml 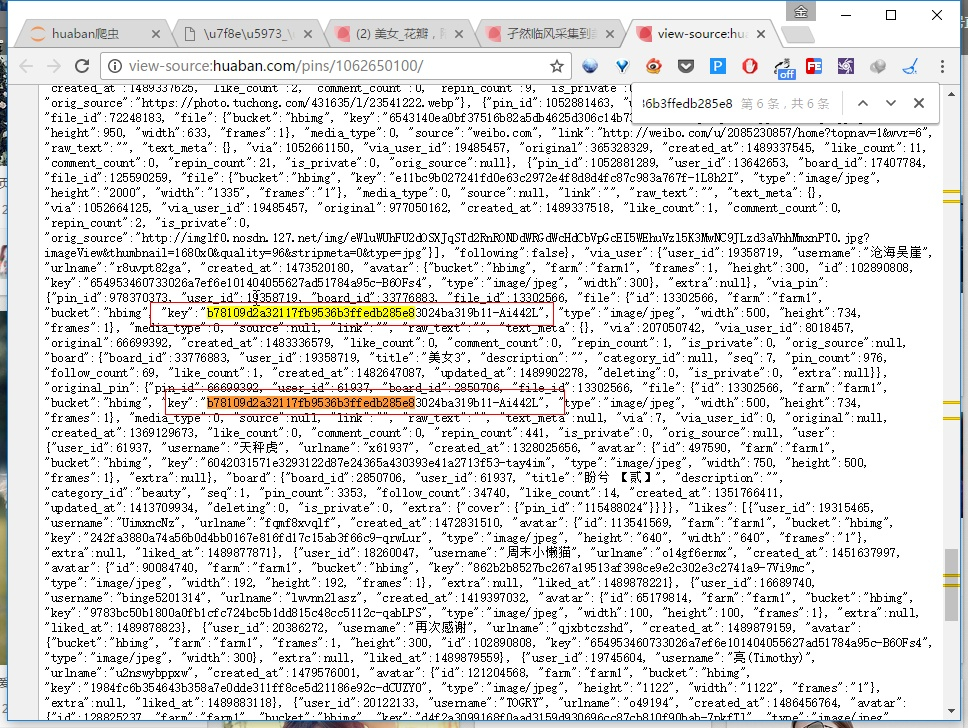
看代码.
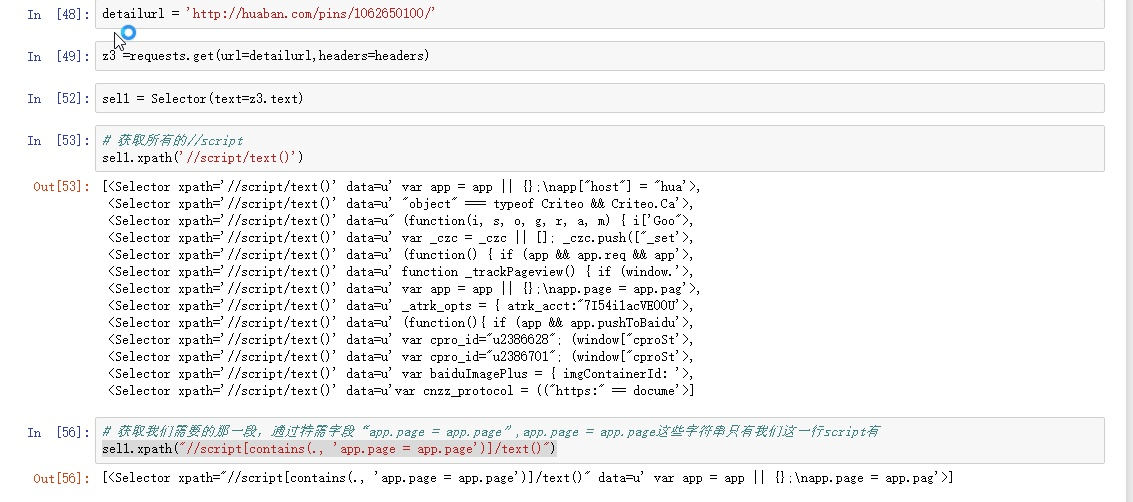
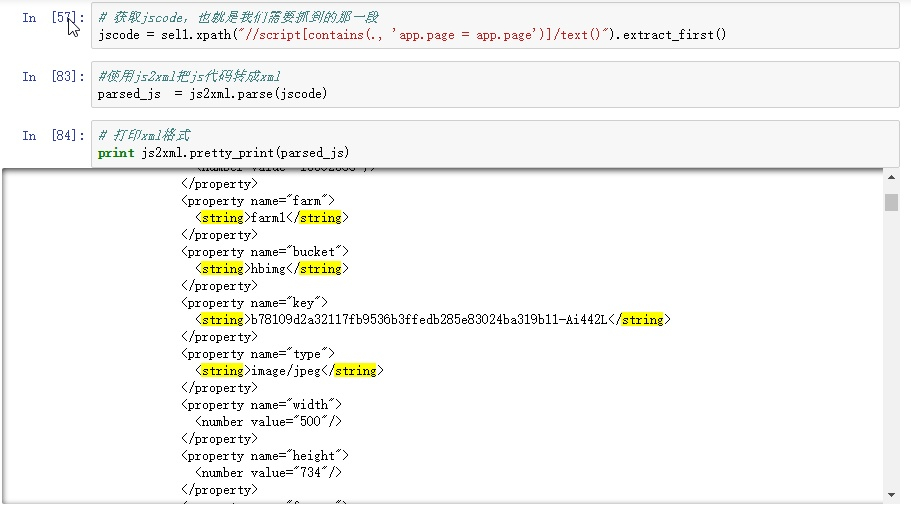
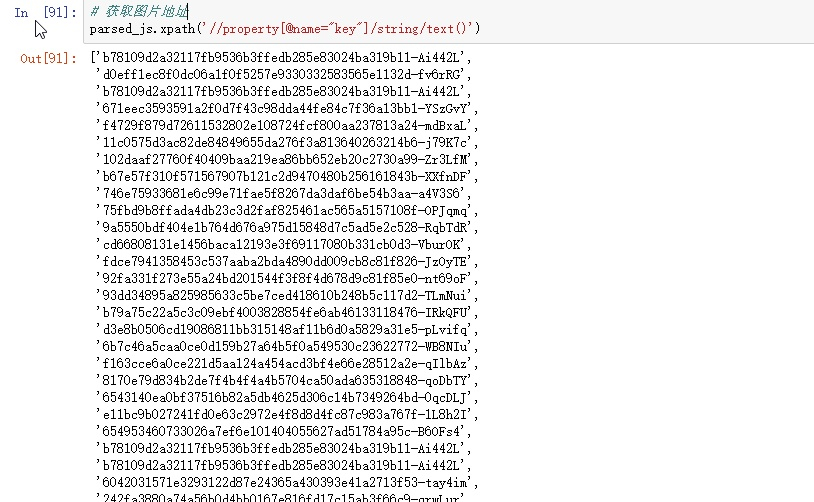
就这样,我们已经把图片地址获取到了,只需要拼接下即可(记得去下重)
最后再次总结一下
看完本篇文章后,你应该要
- 能知道如何抓取异步加载的请求
- 了解js2xml的用法
- 了解headers的用法
最后代码都在 kimg1234/pachong(https://github.com/kimg1234/pachong/blob/master/huaban%E7%88%AC%E8%99%AB.ipynb)
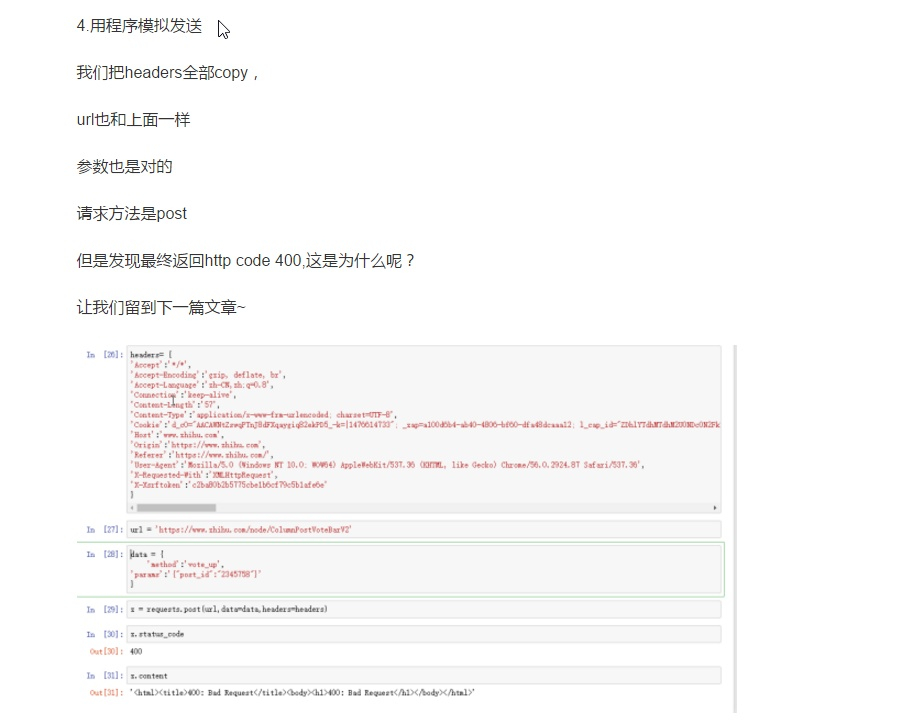
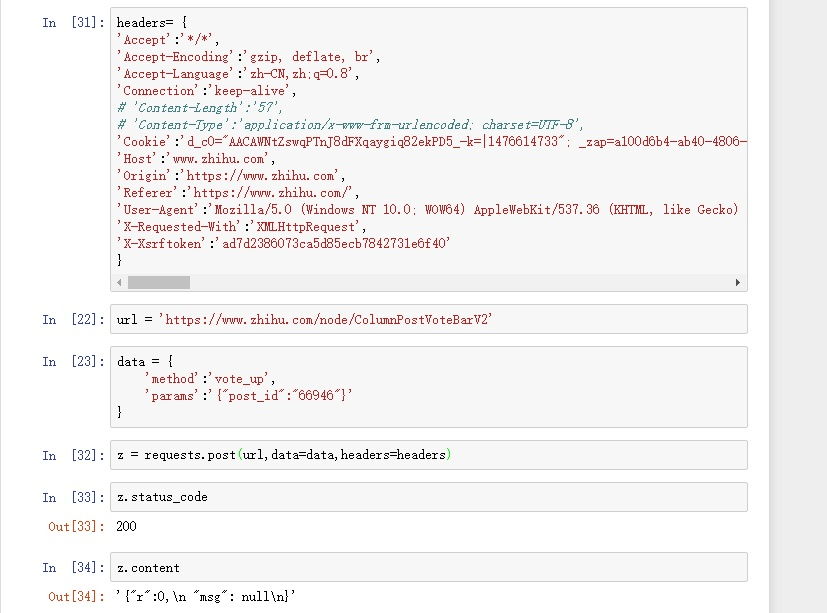
其实解决方法也挺简单的,就是把content-type这一行注释掉。
那么为什么注释掉就可以了呢?请仔细研究研究http协议。。。
本文作者:高金
本文地址: https://igaojin.me/2018/02/03/爬虫之异步加载-实战花瓣网/
版权声明:转载请注明出处!
